David L. Tennenhouse and David J. Wetherall[*]
Laboratory for Computer Science, MIT
Active networks allow users to inject customized programs into the nodes of the network. In this paper, we describe our vision of an active network architecture, outline our approach to its design, and survey the technologies that can be brought to bear on its implementation. In the course of this presentation we identify a number of research questions to be addressed and propose that the research community mount a joint effort to develop and deploy a wide area ActiveNet.
Traditional data networks passively transport bits from one end system to another. Ideally, the user data is transferred opaquely, i.e., the network is insensitive to the bits it carries and they are transferred between end systems without modification. The role of computation within such networks is extremely limited, e.g., header processing in packet-switched networks and/or signaling in connection-oriented networks.
Active Networks break with tradition by allowing the network to perform customized computations on the user data. For example, a user of an active network could send a customized compression program to a node within the network (e.g., a router) and request that the node execute that program when processing their packets. These networks are "active" in two ways:
Our work is motivated by both technology "push" and user "pull". The technology "push" is the emergence of "active technologies", compiled and interpreted, supporting the encapsulation, transfer, interposition, and safe and efficient execution of program fragments. Today, active technologies are applied within individual end systems and above the end-to-end network layer; for example, to allow Web servers and clients to exchange program fragments. Our innovation is to leverage and extend these technologies for use within the network - in ways that will fundamentally change today's model of what is "in" the network.
The "pull" comes from the ad hoc collection of firewalls, Web proxies, multicast routers, mobile proxies, video gateways, etc. that perform user-driven computation at nodes "within" the network. Despite architectural injunctions against them, these nodes are flourishing, suggesting user and management demand for their services. We are developing the architectural support and common programming platforms to support the diversity and dynamic deployment requirements of these "interposed" services. Our goal is to replace the numerous ad hoc approaches to their implementation with a generic capability that allows users to program their networks.
There are three principal advantages to basing the network architecture on the exchange of active programs, rather than static packets:
In the next section we provide a description of some of the "lead user" applications that motivate an architecture that facilitates computation within the network. In section 3, we provide an overview of active networks, a high-level perspective on how we propose to organize their platforms and an introduction to the research issues that must be addressed. Section 4 describes the "instruction set" issues associated with an interoperable programming model and how "active technologies" can be leveraged to effect the safe and efficient evaluation of capsules. We then discuss the management of node resources, such as storage and link bandwidth, followed by our plan for the deployment of a research ActiveNet. We realize that our work challenges some key assumptions that have guided recent networking research and so the final sections of this paper discuss the architectural and structural questions raised by our approach.
Recently, there has been considerable interest in agent technologies, which allow mobile code to travel from clients to servers, and in Web applets, which allow mobile code to travel from servers to clients. Active networks bridge this dichotomy by allowing applications to dispatch computation to where it is needed.
We are encouraged by the observation that a number of lead users have pressing requirements for the transparent interposition of computation within the network. These include the developers of:
A further argument in favor of using active technologies for web caching is that a significant fraction of web pages are dynamically computed and not susceptible to traditional (passive) caching. This suggests the development of web proxy schemes that support "active" caches that store and execute the programs that generate web pages.
Similarly, "nomadic agents" [2] and "gateways" are nodes that support mobility. They are located at strategic points that bridge networks with vastly different bandwidth and reliability characteristics, such as the junctions between wired and wireless networks. Application-neutral work on TCP "snooping" [3] improves the performance of TCP connections by retaining per-connection state information at wireless base stations. Application-specific services performed at gateways include file caching and the transcoding of images [4] . The InfoPad [5] takes the process even further, by instantiating user-specific "pad servers" supporting a range of applications, such as voice and hand-writing recognition, at intermediate nodes.
"Sensor fusion" is an example of a domain that may leverage interposed computation. Applications of sensor fusion, such as simulation and remote manipulation, allow users to "see" composite images constructed by fusing information obtained from a number of sensors. Bandwidth and latency considerations suggest that this domain may benefit from interposed computation.
In this section, we provide an overview of active networks - highly programmable networks that perform computations on the user data that is passing through them. We distinguish two approaches to active networks, discrete and integrated, depending on whether programs and data are carried discretely, i.e., within separate messages, or in an integrated fashion. We then provide a high-level description of how active nodes might be organized and describe a node programming model that could provide the basis for cross-platform interoperability.
The separation of program execution and loading might be valuable when it is desirable for program loading to be carefully controlled or when the individual programs are relatively large. For example, program loading could be restricted to a router's operator who is furnished with a "back door" through which they can dynamically load code. This "back door" would at minimum authenticate the operator and might also perform extensive checks on the code that is being loaded. Note that allowing operators to dynamically load code into their routers would be useful for router extensibility purposes, even if the programs do not perform application- or user-specific computations.
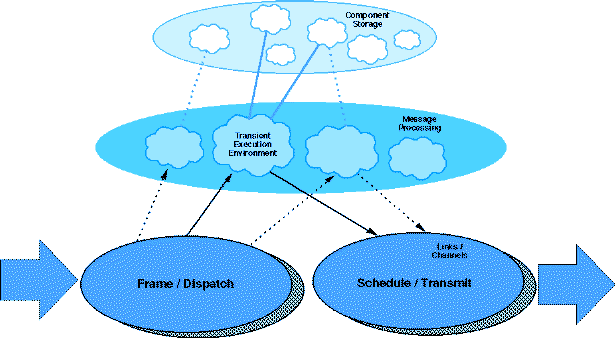
Figure 1. Active Node Organization
Figure 1 provides a conceptual view of how an active node might be organized. Bits arriving on incoming links are processed by a mechanism that identifies capsule boundaries, possibly using the framing mechanisms provided by traditional link layer protocols. The capsule's contents are dispatched to a transient execution environment where they can safely be evaluated. We hypothesize that programs are composed of "primitive" instructions, that perform basic computations on the capsule contents, and can also invoke external "methods", which may provide access to resources external to the transient environment. The execution of a capsule may result in the scheduling of zero or more capsules for transmission on the outgoing links and/or changes to the non-transient state of the node. The transient environment is destroyed when capsule evaluation terminates.
In the following paragraphs we discuss some ways in which active networks could be leveraged to support a variety of traditional functions, such as IP packet processing, connections, flows, routing protocols, etc. These examples are meant to provide insight into the "flavor" of the networks we envision and establish the groundwork for the discussion of the programming model and implementation technologies which follows.
In simple applications, a capsule's actions on visiting a node are to compute its "next hop" destination(s) and schedule zero or more (possibly modified) copies of itself for onward transmission on selected links. It will be necessary to provide mechanisms for determining and naming the link(s) on which an outgoing capsule is to be transmitted. In the IP protocol, this mechanism is "built-in" to every node and individual packets need only carry their destination address - they need not have knowledge of the links they traverse. In pure source routing schemes, each message carries the identities of all of the links it traverses. We hope to develop an intermediate approach, in which capsules can dynamically enumerate and evaluate the paths available at a node without requiring detailed knowledge at the time the capsule is originally composed.
An important question concerns the degree to which a capsule program can access objects, such as routing tables, that lie beyond the transient execution environment. In a restricted approach, capsules could be largely self-contained. Although sufficient to implement some interesting programs, such as source routing, this model is somewhat confining. In the following paragraphs we discuss three ways in which programs could reach beyond the capsule's transient environment:
Many capsules will require access to node-specific information and services, such as routing tables and the state of the node's transmission links. Using built-in components that provide access to this information, one could design capsules whose evaluation performs similar processing to that performed on the header of an IP datagram. Multi-cast and option processing instructions could be included in the capsules that require them. Whereas the traditional IP approach calls for the code to be fixed and built-into in the router, in the active case the program performing the processing is flexible and carried with the data.
For migration purposes, we could develop standardized components that implement the existing Internet protocol types. A capsule carrying an embedded IPv4 datagram could contain a single instruction of the form "execute the IPv4 method on the remainder of the payload". To put matters in perspective, we can think of existing routers as an extremely restricted subset of active nodes, in which the capsule "program" is carried in the IP protocol type field. The instruction set is restricted to pre-defined methods that correspond to the known protocol type field values and implement the standardized functionality specified by the IETF.
A similar approach could be used to realize "flows" [6] , which are somewhat "softer" than connections. Every capsule would include code that attempts to locate and use its "flow" state at the nodes it traverses. However, flow capsules are somewhat more robust than those used during connections in that the flow state is not essential to the capsule's successful execution. If a flow capsule encounters a node that has no relevant state information, it dynamically generates the required data, uses it for its own purposes and leaves it behind for the convenience of later capsules. The network nodes can treat flow states as "soft state" values that are "cached" and can be disposed of if necessary. In this respect, flows are less demanding than connections on the robustness of node storage. Of course, our active connections and flows are considerably more powerful than those of present day systems, in that the "state" left behind is in the form of programs that can perform application- or user- specific processing on the transmitted data.
Eventually, we hope to develop new network programming schemes that go beyond traditional connections and flows. For example, capsules could be programmed to rendezvous at a node by arranging for the first arriving capsule(s) to set some state information and then "sleep" until the remaining capsules have arrived. The capsules could then engage in some joint computation, such as may be used in sensor fusion applications or the pruning of multi-cast trees.
Finally, we note that capsules capable of modifying the node's storage provide a uniform mechanism for the implementation of background node functions. Routing protocols and routing table updates could be implemented in capsules as could network management functions, such as those provided by SNMP. Long-lived housekeeping functions could also be implemented in this manner, though in their case the "transient" execution environment might survive until the node is reset.
An interesting scheme would be to provide a mechanism that dynamically resolves references to external methods. Instead of capsules explicitly loading methods into the non-transient storage of the node, the node could contain a "cache" of known external methods and be equipped with a mechanism that allows it to locate and dynamically load methods on demand.[1] Although such a "demand" approach might suffer latency problems when a new application is started, this could be offset by allowing capsules that "prime" the cache when cache faults are anticipated.
The distinction between the "explicit" and "demand" loading schemes is closely related to the broader distinction we have made between "discrete" and "integrated" approaches to active networks. The "explicit" and "discrete" cases distinguish program loading as an explicit activity that must be completed prior to usage. In contrast, the "demand" and "integrated" cases offer increased flexibility with respect to determination and timing. Of course, this flexibility comes at some cost in terms of the sophistication of the mechanisms required to support safe and efficient loading of programs.
We find it convenient to distinguish between: issues surrounding the representation and evaluation of the capsules themselves; and safe access to external methods and resources.
In section 4, we outline the functionality that is required and discuss mechanisms that can be used to support the safe and efficient execution of capsules. We discuss how "active technologies", developed within the programming language and operating system communities, can be used to prevent unauthorized access to resources that lie beyond the boundaries of the transient execution environment into which a capsule is dropped.
In section 5, we discuss resource management, which is an important issue in active nodes - these nodes are components of the shared infrastructure and their users must be protected from each other to a degree that is typically not required within personal computers or even group servers. The programming model must deal with two issues associated with node resources: interoperability and resource management. The interoperability requirement is for a common model of the resources available at a node that encompasses physical resources, such as node storage and link bandwidth, and logical resources, such as routing tables. Resource management issues include resource allocation and capsule authentication and authorization.
In this section we discuss: the language(s) in which capsule programs are expressed; and mechanisms that can support their safe and efficient execution. Our overall approach is to evaluate each capsule within the context of a transient execution environment whose lifetime is the interval during which the capsule is evaluated at a given node. Safety properties are provided by restricting the actions that can be performed and their scope, e.g., their access to storage and other node resources.
The set of primitive actions will be extended through the addition of external method invocation, which provides access to resources beyond the transient environment. Some of these external methods will leverage the same primitive actions and will also be evaluated in a closed environment, i.e., with a sharp distinction between their self-contained actions and their access to other methods. Others will access the built-in "API" of the node's run-time environment or embedded operating system. The API of active network nodes will be distinguished by the availability of methods that are tailored to the network environment, such as the efficient copying of capsules and sophisticated control over the scheduling of transmission resources.
For interoperability purposes all of the active nodes along a capsule's path should be capable of evaluating the capsule's contents.[2] There are three well known ways of achieving this level of portability/mobility:
In the field of parallel processing, "active messages" [7, 8] stressed efficiency over mobility by reducing the "program" to a single instruction - each message invokes an application-specific handler resident at the recipient. The handler provides a low overhead mechanism for dispatching arriving messages - so that they can be treated as self-scheduling computations. These systems, which targeted communication internal to a single parallel processor complex, did not address the safety issues relevant to shared infrastructures.
The advent of heterogeneous distributed systems and internetworking has accelerated the pace of research. The x-kernel [9] supports the composition of protocol handlers by providing a regular architecture for stacking them and by automating the dispatch process. Other efforts [10-12] have focused on less friendly environments by improving both the safety and efficiency with which handlers can be implemented. Most recently, there have been efforts to jointly address all three issues - mobility, safety and efficiency - under the banners of configurable operating systems, agents, mobile applets and other schemes related to the World Wide Web.
In the following paragraphs, we discuss the available technologies in terms of the program encoding approaches - source, intermediate, or platform dependent binary - and then introduce "on-the-fly" compilation, a complementary technology that is also of interest.
On-the-fly compilation technologies may prove crucial to the viability of our architecture. Modern IP routers achieve reasonable performance through careful tuning of their "fast paths", typically by optimizing a minimal instruction sequence that processes the vast majority of the traffic and relegates the more complex (and less frequently used) cases to other modules. An active node might achieve a similar performance boost by monitoring its traffic and dynamically generating (and compiling) a fast path program that streamlines the execution of the most common capsule programs.
Our plan is to adopt a Java-like instruction set as the basis for ActiveNet interoperability and code mobility. One of the benefits of the present IP packet format is that it enables an "hourglass" architecture in which a variety of upper layer protocols can operate over a wide range of network substrates. An intermediate instruction set will provide an analogous "hourglass" that facilitates mobility. A range of programming languages and compilers can be used to generate highly mobile intermediate code that can be executed on a wide range of hardware platforms.
Nonetheless, we believe that it will also prove practical and attractive to provide "extensions" that allow users and node implementors to leverage source and binary technologies. The architectural trick will be to enable these technologies, while retaining the intermediate instruction set as a fallback point that ensures interoperability. We have considered the following extensions:
Having identified the requirement for common programming models, we are not suggesting that a single model be immediately standardized. The tensions between available programming models and implementation technologies can sort themselves out in the research "marketplace" as diverse experimental systems are developed, fielded, and accepted or rejected by users. For example, if the marketplace identifies two or three encodings as viable, then nodes that concurrently support all of them will emerge. As systems evolve to incorporate the best features of their competitors, we expect that a few schemes will become dominant.
Active Networks will provide the building blocks for a shared information infrastructure that transcends many administrative domains. Accordingly, their design must address a range of "sharing" issues that are often brushed over in systems that are used in less public environments. We focus on two of the issues that must be addressed. For inter-operability, capsule programmers must have a shared understanding as to what the resources are and how they are named. Secondly, mechanisms must be provided to limit access to scarce or sensitive resources.[5]
The class specifications of many logical resources, such as application-specific external methods or flow states, may be private in the sense that they need only be known to capsules generated by the relevant application. However, there will be a need for interoperable class specifications for some resources, such as routing tables. In this case, we hope to leverage existing notations, such as those used for SNMP Management Information Bases (MIBs). Where possible, we will leverage the existing MIB specifications themselves, which should facilitate interoperation between the ActiveNet and the existing Internet.
We assume that cryptography will provide the basis for the validation mechanism, but may use a combination of schemes to reduce per-capsule overheads. For example, a public key scheme could be used to perform an initial authentication that establishes "soft state" that is then used by a lighter weight per-capsule signature algorithm. We are particularly interested in recent work on inexpensive techniques that provide less security for individual messages, but still defend against large scale attacks [21] .
Ultimately, this may be one of the most important "open" questions with respect to active networks. We envision an ActiveNet with as many or more administrative domains as the Internet (which is still growing), and administrators will be swamped if they are expected to manually coordinate the detailed authorization information This is another place where complexity, in this case administrative complexity, could overwhelm the infrastructure.
We suggest that interested researchers pool their talents in an effort to deploy a wide area ActiveNet. This experimental infrastructure could be overlaid on existing substrates, such as the Internet and the VBNS, obviating the need for dedicated transmission facilities. Although most of the ActiveNet nodes could be located at participating research sites, provision should be made to locate nodes at strategic locations not normally accessible to researchers, e.g., the NAPs of the Internet. If a research ActiveNet proves successful, it could be extended to assume direct control over the underlying transmission resources and for use within the public infrastructure.
In assembling a collection of nodes into an ActiveNet it will be necessary to deal with many of the issues that have been addressed in the design of the current Internet - topology discovery, routing, etc. Initially, we expect to adopt the techniques used in the Internet. However, researchers should also investigate new algorithms that leverage the availability of active nodes.
Eventually, it will be important to converge on an interoperable programming model that will achieve for active networks what IP standardization has for the Internet. However, the connectivity available through existing substrates will makes it possible to deploy a multiplicity of programming models in parallel, affording the research community an opportunity to explore alternative programming models and node implementations. It will be particularly important to engage application developers and users in the development of customized software components that exercise this "architecture of architectures".
Conventional network architectures separate the upper (end-to-end) layers from the lower (hop-by-hop) layers. The network layer bridges these domains and enables interoperability by providing a fixed application- and user- neutral service that supports the exchange of opaque data between end systems.
Active networks challenge this traditional thinking in a number of ways: the computations performed within the network can be dynamically varied; they can be user- and/or application-specific; and the user data is accessible to them. We realize that this break with tradition raises a number of important questions, some of which are addressed in the following responsa.
In contrast, active nodes are capable of performing many different computations (i.e., executing many different programs) for different groups of users. However, the nodes must all support an "equivalent" computation model. Thus, network layer interoperability is based on an agreed program encoding and computation environment instead of a standardized packet format and fixed computation.
Architecturally, we are bumping up the level of abstraction at which interoperability is realized. There is still an hourglass - but the abstraction at its thinnest point has been made programmable.
It is the "intelligence" or control over the network-based computation that has been migrating to the edges, allowing users to exercise greater control over their networks. Experience suggests that the two go hand in hand - increasing the flexibility of the computation performed within the network enables the deployment of even greater computational power at the edges.
Current thinking concerning network architecture has its roots in the layering of abstractions codified in the OSI Reference Model [26] . Although the model has proven quite useful it is beginning to show cracks that should be addressed:
While locating computation within the network may appear to contradict this guideline, we note that the argument pertains to the placement of functionality - it does not suggest that the choice of functions that are appropriately located within the network cannot be application-specific. If anything, active networks allow this guideline to be followed more carefully, by allowing applications to selectively determine the partitioning of functionality between the end points and intermediaries.
In this paper we have described our vision of an active network architecture that can be programmed by its users. We have also called for community participation in an effort to develop and deploy a research ActiveNet. In the course of this presentation we have raised a number of architectural issues and research questions that remain to be addressed.
We expect that active networks will enable a range of new applications in addition to the "lead " applications that already rely on the interposition of customized computation within the network. However, we believe that this work will also have broader implications, on how we think about networks and their protocols; and on the infrastructure innovation process.
We are applying a programming language perspective to networks and their protocols. In place of protocol "stacks", we anticipate the development of protocol components that can be tailored and composed to perform application-specific functions. These protocol components will leverage the tools of the modern programming trade - encapsulation, polymorphism and inheritance. Within our own research group, we are setting out to create a "Smalltalk of networking" and are interested not just in the "language" itself but also in the class hierarchy, etc. that will develop around it.
Our enthusiasm is tempered by the realization that suggestions for object-oriented approaches to networking surface every five to ten years, and have had little impact on mainstream research. However, we believe that it is now time to make a large scale effort towards their realization. The availability of active technologies and lead applications - in conjunction with rising processing power and bandwidth - presents opportunities that were not previously available.
Active networks will address the mismatch between the rate at which user requirements can change, i.e., overnight, and the pace at which physical assets can be deployed. They will accelerate the pace of innovation by decoupling network services from the underlying hardware and by allowing new services to be demand loaded into the infrastructure. In the same way that IP enabled a range of upper layer protocols and transmission substrates, active networks will facilitate the development of new network services and hardware platforms. Furthermore, the process will be user-driven. The widespread availability of new services will depend on their acceptance in the marketplace, without being delayed by vendor consensus and standardization activities. Similarly, hardware vendors will seek competitive advantage by optimizing their platforms to suit changing workloads.
Conventional network routers are based on proprietary hardware platforms that are bundled with customized software. Active networks present an opportunity to change the structure of the networking industry, from a "mainframe" mind-set, in which hardware and software are bundled together, to a "virtualized" approach in which hardware and software innovation are decoupled [29] . A market for "shrink-wrapped" network software will facilitate innovation by:
In summary, passive network architectures that emphasize packet-based end-to-end communication have served us well. However, as our lead users demonstrate, computation within the network is already happening - and it would be unfortunate if network architects were the last to notice. It is now time to explore new architectural models, such as active networks, that incorporate interposed computation. We believe that such efforts will enable new generations of networks that are highly flexible and accelerate the pace of infrastructure innovation.
The authors wish to thank Jennifer Steiner Klein, who assisted in the drafting and technical editing of the Manuscript, Rachel Bredemeier who assisted with layout and the bibliography, and Sun Microsystems Laboratories, who provided "seed" funding for this project. This work has been influenced by discussions with a number of researchers, especially: Deborah Estrin, Henry Fuchs, Butler Lampson, Paul Leach, Gary Minden, Herb Schorr, Scott Shenker and Dave Sincoskie.
2. Kleinrock, L. Nomadic Computing (Keynote Address). in Int. Conf. on Mobile Computing and Networking. 1995. Berkeley, CA.
3. Balakrishnan, H., et al. Improving TCP/IP Performance over Wireless Networks. in Int. Conf. on Mobile Computing and Networking. 1995. Berkeley, CA.
4. Amir, E., S. McCanne, and H. Zhang. An Application Level Video Gateway. in ACM Multimedia `95. 1995. San Francisco, CA.
5. Le, M.T., F. Burghardt, and J. Rabaey. Software Architecture of the Infopad System. in Mobidata Workshop on Mobile and Wireless Information Systems. 1994. New Brunswick, NJ.
6. Clark, D.D. The Design Philosophy of the DARPA Internet Protocols. in ACM Sigcomm Symposium. 1988. Stanford, CA.
7. von Eicken, T., et al. Active Messages: A Mechanism for Integrated Communication and Computation. in 19th Int. Symp. on Computer Architecture. 1992. Gold Coast, Australia.
8. Agarwal, A., et al. The MIT Alewife Machine: Architecture and Performance. in 22nd Int. Symp. on Computer Architecture (ISCA `95). 1995.
9. O'Malley, S.W. and L.L. Peterson, A Dynamic Network Architecture. ACM Transactions on Computer Systems, 1992. 10(2) p. 110-143.
10. Jones, M. Interposition Agents: Transparently Interposing User Code at the System Interface. in 14th ACM Symp. on Operating Systems Principles. 1993. Asheville, NC.
11. Bershad, B., et al. Extensibility, Safety and Performance in the SPIN Operating System. in 15th ACM Symp. on Operating Systems Principles. 1995.
12. Engler, D.R., M.F. Kaashoek, and J. O'Toole Jr. Exokernel: An Operating System Architecture for Application-Level Resource Management. in 15th ACM Symp. on Operating Systems Principles. 1995.
13. Borenstein, N. Email with a Mind of its Own: The Safe-Tcl Language for Enabled Mail. in IFIP International Conference. 1994. Barcelona, Spain.
14. Gosling, J. and H. McGilton, The Java Language Environment: A White Paper, 1995, Sun Microsystems.
15. Gosling, J. Java Intermediate Bytecodes. in SIGPLAN Workshop on Intermediate Representations (IR95). 1995. San Francisco, CA.
16. Wahbe, R., et al. Efficient Software-Based Fault Isolation. in 14th ACM Symp. on Operating Systems Principles. 1993. Asheville, NC.
17. Colusa Software, Omniware: A Universal Substrate for Mobile Code, 1995, Colusa Software.
18. Engler, D.R., W.C. Hsieh, and M.F. Kaashoek. `C: A Language for High-Level, Efficient, and Machine-Independent Dynamic Code Generation. in 23rd Annual ACM Symp. on Principles of Programming Languages (to appear). 1996. St. Petersburg, FL.
19. Shenker, S., D.D. Clark, and L. Zhang. Services or Infrastructure: Why we Need a Network Service Model. in 1st Int'l Workshop on Community Networking. 1994. San Francisco, CA.
20. Liskov, B., M. Day, and L. Shrira, Distributed Object Management in Thor, in Distributed Object Management, T. Ozsu, et al., Editor. 1993, Morgan Kaufmann: San Mateo. p. 79-91.
21. Manasse, M.S. The Millicent Protocols for Electronic Commerce. in 1st USENIX Workshop on Electronic Commerce. 1995. New York, NY.
22. Bell, D.E. and L.J. LaPadula, Secure Computer Systems: Unified Exposition and Multics Interpretation, 1976, MITRE Corp.
23. Wilkes, M.V. and R.M. Needham, The Cambridge CAP Computer and Its Operating System. Operating and Programming Systems Series, ed. P.J. Denning. 1979, New York City: North Holland.
24. Sollins, K.R. Cascaded Authentication. in Proceedings of the 1988 IEEE Symposium on Security and Privacy. 1988. Oakland, CA.
25. Burrows, M., M. Abadi, and R. Needham, A Logic of Authentication. ACM Transactions on Computer Systems, 1990. 8(1) p. 18-36.
26. ISO, Information Processing Systems - Open Systems Interconnection - Basic Reference Model, 1984, ISO.
27. Clark, D.D. and D.L. Tennenhouse. Architectural Considerations for a New Generation of Protocols. in ACM Sigcomm Symposium. 1990.
28. Saltzer, J.H., D.P. Reed, and D.D. Clark, End-To-End Arguments in System Design. ACM Transactions on Computer Systems, 1984. 2(4) p. 277-288.
29. Tennenhouse, D., et al., Virtual Infrastructure: Putting Information Infrastructure on the Technology Curve. Computer Networks and ISDN Systems (to appear), 1996.