-
Introduction
to telecommunications
-
Communication
Protocols
Communication is a complex process. Consider that
you want to communicate with another person. First you have to catch that
persons attention, and then you need to express your intention to communicate.
That might not be as easy as you think, because the person can be blind,
death, or a foreigner, who does not speak the same language as you do.
To communicate any two entities require establishing
certain rules that can be expressed by a communication protocol.
Two people talking in English use this language to
encode information. It covers:
They cannot speak at the same time, so usually
the sentences are exchanged in a synchronized way. This introduces a requirement
on
These aspects of communication are handled by protocols.
Computers also require protocols to communicate.
-
Protocol
Stack
There are plenty of computer makers, who are flooding
the market with all kinds of computers. Certain standards are needed to
enforce communication protocols, so the user of different machines can
still communicate.
This task is not easy, as there are plenty of players,
whose goals are contradictory. The International Standardization Organization
(ISO) attempted to deliver such a standard by designing the Open System
Interconnection (OSI) communication model. Unfortunately, before everybody
agreed on all details, most of the world was using other de-facto standards
like TCP/IP. Nevertheless, many ideas put forward in the OSI model
made it through to the competing technologies. The OSI model is still used
to explain the basics of data communication protocols.
The basic idea is the protocol stack. It separates
the communicating application from the details of those aspects of communication
that are irrelevant to that application.
For example, a person trying to read an online newspaper
is not interested in how the newspaper appeared on the screen. The application
(e.g., a browser) does not care what were the details of the network that
brought the information being presented to the user. At that level, it
is irrelevant whether the physical link was a wire or a fiber, or whether
ATM switches were involved in the communication.
Each layer presents a set of services for
the layer immediately above it and can use the services provided by the
layer immediately below it. The services are accessed through service
access points (SAP). In that way, many entities at a given layer
can access services at the layer below at the same time. For example, two
applications can exchange data with others simultaneously.
A layer can be exchanged for another that provides
the same set of services. Therefore, various underlying communication technologies
can be used transparently.
At each level, the perception of the peer is confined
to that level, so there is an illusion of a direct connection. Only the
protocol at this layer is visible. The details of the communication that
occur at the lower levels are transparent.
Each communicating party has to implement the stack.
Any message that is to pass through the communication link has to go down
through all of the layers at the source. The message moves up the stack
at the target.
At each layer, certain control information is attached
to the message. This is called a header. The combination of the
data incoming from the higher layer and the header constitutes a protocol
data unit (PDU). In that way, the size of the message passing
through the protocol stack increases at each layer.
At the receiver, the protocol data units are stripped
off their headers. The protocol handler uses the control information. The
remaining part is passed to the next higher layer as is or several PDUs
can be combined into one chunk of data that is passed up the stack.
Headers may contain information needed for:
-
segmentation and re-assembly
-
addressing
-
connection control
-
sequencing
-
error recovery
-
flow control
-
multiplexing
-
transmission services
-
Connection Control
There are two fundamental types of protocols:
connection-oriented
and connection-less. The path that every PDU has to travel in a
connection-oriented communication is the same. The connection, which is
called a virtual circuit (VC), is maintained for the duration of
the communication. It closely resembles a conversation over a telephone
line (and hence the name). Protocol handlers can use the connection identifier
as an address for routing the data.
Each virtual circuit can be additionally organized
to carry a number of virtual channels, so multiple connections can
be handled over a single VC.
In the connection-less communication, each PDU is
handled independently and may be routed through a unique path. At every
node, the message, which is called a datagram, is sent further according
to a certain routing algorithm. There are a number of routing strategies
involving either static or dynamic (adaptive) algorithms.
-
Addressing
There may be many computer nodes involved
in a communication process between two parties. It is analogous to a telephone
conversation that may be carried out over a number of telephone exchanges.
Therefore, each message must indicate its target, so at each node it can
be routed toward that target. A part of the control information in the
header specifies the destination of the PDU. Very often, the source also
is included along with other related information like addressing level
(e.g., IP address), scope (e.g., global) and mode (unicast, multicast
or broadcast).
-
unicast sending messages to one party (one target)
-
multicast sending messages to many parties (multiple
targets)
-
broadcast sending messages to anybody, who is listening.
-
Segmentation and re-assembly
Very often, long messages are split into smaller
chunks to increase reliability and efficiency, and to accommodate available
services. For example, a human translator must focus on translating relatively
short phrases. In the extreme, no translation could occur. Imagine translating
a book after hearing it just once!
-
Sequencing
To maintain a coherent communication the parties
have to exchange information in an orderly fashion. If you ask two questions
about time and temperature, you want to get the time first and the temperature
next. Even more so, if the messages are segmented. A human translator must
translate every phrase in order, because otherwise the whole speech would
be hard to understand. Therefore, PDUs are assigned sequence numbers that
can be used to ensure that the flow of information is chronological.
-
Error recovery
A sequence number is one of several types of control
information that might be used to detect and recover from errors. A simplest
example might be a request to re-send the message that has not managed
to arrive before another message with a higher sequence number. There are
many elaborated schemes involving message buffering that built upon this
simple strategy. For example, a number of messages can be buffered for
a period of time to give each message a window of opportunity to arrive
on time. Only if a message is still missing after the maximum capacity
of the buffer has been reached or the time allocated has been exceeded
will a request for a re-transmission be issued.
It is hard to imagine a human translator buffering
many phrases in an online translating process. Nevertheless, an analogous
scenario can arise if the phrases are delivered in writing on numbered
sheets. If one of the sheets were missing, then the source would be asked
to make another copy of the missing phrase.
-
Flow control
If the consumption of the messages at the target
is slower than the arrival rate, then the source might be requested to
slow or stop the transmission. Similar scenario may occur between any two
communicating nodes.
A corresponding event in the example with translating
a speech might be a request from the translator to slow the speech.
The generalization of the flow control issue is congestion
control. The problem arises when the capacity to handle messages is lower
than the number of arriving messages. There are a number of elaborate schemes
for congestion control, which use control information from message headers.
-
Multiplexing
To increase the utilization of the available resources
communication links are usually shared between many communicating parties.
The messages that arrive from such a link have to be routed to various
destinations. The control information in the header makes it possible to
associate a given PDU with its target. It can happen at an intermediate
node as well, as the further route is determined.
-
OSI
Model
There are seven layers in the OSI model of a communication
stack, which are shortly described in the table. The OSI model strictly
forbids the use of services provided by layers other than the next lower
layer. It makes the model very open, but also awkward at times.
|
7
|
Application
|
Application layer provides
for application-oriented protocols that the applications use to process
information. |
|
6
|
Presentation
|
Presentation layer provides
the application layer with data structuring and manipulation services. |
|
5
|
Session
|
Session layer provides
the higher layers with services for maintaining a communication session
between the communicating parties. |
|
4
|
Transport
|
Provides services that
ensure coherent message transfer between the source and the target. |
|
3
|
Network
|
Provides services to route
messages between two nodes in a network. |
|
2
|
Data
|
Provides services for
reliable transmission of data over a physical medium. |
|
1
|
Physical
|
Specifies the exchange
rules over a physical media like fiber, copper, wireless, satellite, etc. |
Not all nodes are required to implement a complete
communication stack. For example, a repeater implements only the lowest
two layers of the stack because its role is to just forward the signal.
A router requires the lowest three layers to unpack the message up to the
network header and use the information from it for further routing.
In this course, we are interested in the application
layer, but the transport and network layers are relevant as well. We will
be using the TCP/IP model, which is the basis of the Internet and many
intranets and extranets.
-
TCP/IP
The TCP/IP model has become a de facto standard,
because it was ready when needed, Department of Defense (DoD) sanctioned
its use and the Internet adopted it. The TCP/IP model is managed by the
Internet
Architecture Board (IBA) through its subsidiary, the Internet
Engineering Task Force (IETF). IETF issues Requests for Comments
(RFCs) to obtain proposals for standards from the Internet society.
RFC goes through a series of stages before it becomes a standard.
In the TCP/IP model, the upper three layers of the
OSI model are collapsed into one application layer. Services provided by
any lower layer can be used, as is the case with the ICMP protocol. In
contrast to the OSI model, the protocols at the same level do not have
to provide the same services. Accordingly, protocols cannot be substituted
at will. If protocols share the set of support services provided by protocols
at a certain layer, then they are considered to belong to the next higher
layer.
In this model, when an application (such as an FTP,
Telnet, SMTP or HTTP client) wants to exchange data with a remote peer,
it usually uses the services of the transport layer. It sends individual
datagrams using User Datagram Protocol (UDP) or establishes
connection and sends messages over the connection using Transmission
Control Protocol (TCP). In any event, all messages are divided
into packets that are routed by the handlers of the Internet Protocol
(IP). The packets are routed to the destination node, where they
are reassembled and passed to the corresponding transport layer. Packets
can be further divided into smaller pieces on their way to the target,
but it is done transparently to the transport layer and to the application.
There are a number of routing protocols used to move
packets towards its target. Border Gateway Protocol (BGP)
is widely used to route messages between routers on different networks.
Open
Shortest Path First (OSPF) is predominant as an interior routing
protocol. The protocols are used to exchange routing information between
routers.
-
Internet Protocol
(IP)
Internet Protocol is the glue that keeps the networks
connected into one global super network, the Internet. It is a connection-less
protocol designed to route data packets between nodes independent of the
networks to which they belong. To achieve its objective, IP uses control
information encapsulated in the header, which is added to every routed
message.
From the perspective of this course, the most important
part of the header is the address information. It determines the source
and the target of the message. The source is added automatically, so is
of lesser interest to us. The target has to be provided by the application
that wants to communicate. The IP address can be derived from more abstract
naming schema provided by name servers; e.g., Domain Name System
(DNS).
-
IPv4 Addressing
The current version (4) of IP uses 32-bit addresses.
Dotted
decimal notation is usually used to annotate addresses. It divides
the 32-bit address into four groups of 8 bits, and then translates the
values of each group from binary to decimal. For example, all zeros are
represented by 0.0.0.0, while all ones will be 255.255.255.255. All IP
addresses fall somewhere in between.
The addresses are divided into the following categories
that define certain address spaces:
| Class A |
Directed to
networks with many nodes. Few networks can be accommodated. 126. |
| Class B |
Directed towards
medium size networks. 16382. |
| Class C |
Accommodates
plenty networks with small number of nodes. 2097150. |
| Class D |
Multicast. |
| Class E |
Reserved for
future use. |
Network addresses are assigned by Network
Information Center (NIC). NIC has to be contacted each time
a new network is requested or an address is added or changed. To increase
flexibility of the addressing scheme, networks may be divided into subnetworks.
Managing addressing within subnetworks does not require NICs intervention,
so it has become popular with large organizations. The scheme minimizes
the sizes of the routing tables by addressing subnets rather than all hosts
in the network. A router has to know hosts only in the subnet to which
it belongs. Addressing other subnets is easy if the address is logically
ANDed with a subnet mask.
There are five classes of IP addresses.
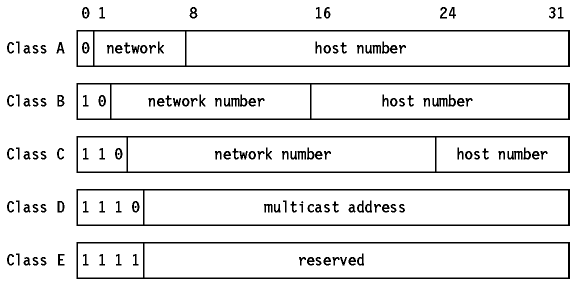
Assigned Classes of Internet Addresses
Note: Two numbers out of each of
the class A, class B and class C network numbers, and two host numbers
out of every network are pre-assigned: the ``all bits 0'' number and the
``all bits 1'' number. These are discussed below in Special IP Addresses.
-
Class A addresses use 7 bits for the network
number giving 126 possible networks (we shall see below that out of every
group of network and host numbers, two have a special meaning). The remaining
24 bits are used for the host number, so each networks can have up to 2(superscript
24)-2 2 to the power 24 minus 2 (16,777,214) hosts.
-
Class B addresses use 14 bits for the network
number, and 16 bits for the host number giving 16382 networks each with
a maximum of 65534 hosts. (The Three Bears Problem)
-
Class C addresses use 21 bits for the network
number and 8 for the host number giving 2,097,150 networks each with up
to 254 hosts.
-
Class D addresses are reserved for multicasting,
which is used to address groups of hosts in a limited area.
-
Class E addresses are reserved for future
use.
It is clear that a class A address
will only be assigned to networks with a huge number of hosts, and that
class C addresses are suitable for networks with a small number of hosts.
However, this means that medium-sized networks (those with more than 254
hosts or where there is an expectation that there may be more than 254
hosts in the future) must use Class B addresses. The number of small- to
medium-sized networks has been growing very rapidly in the last few years
and it was feared that, if this growth had been allowed to continue unabated,
all of the available Class B network addresses would have been used by
the mid-1990s. This is termed the IP Address Exhaustion problem. The problem
and how it is being addressed are discussed in The IP Address Exhaustion
Problem below
One point to note about the split of an
IP address into two parts is that this split also splits the responsibility
for selecting the IP address into two parts. The network number is assigned
by the InterNIC, and the host number by the authority which controls the
network. As we shall see in the next section, the host number can be further
subdivided: this division is controlled by the authority which owns the
network, and not by the InterNIC.
-
Subnets
Due to the explosive growth of the Internet,
the use of assigned IP addresses became too inflexible to allow easy changes
to local network configurations. These changes might occur when:
-
A new physical network is installed at a location.
-
Growth of the number of hosts requires splitting
the local network into two or more separate networks.
To avoid having to request additional
IP network addresses in these cases, the concept of subnets was
introduced.
The host number part of the IP address
is sub-divided again into a network number and a host number. This second
network is termed a subnetwork or
subnet. The main network
now consists of a number of subnets and the IP address is interpreted as:
<network number><subnet number><host number>
The combination of the subnet number and the
host number is often termed the ``local address'' or the ``local part''.
``Subnetting'' is implemented in a way that is transparent to remote networks.
A host within a network which has subnets is aware of the subnetting but
a host in a different network is not; it still regards the local part of
the IP address as a host number.
The division of the local part of the IP
address into subnet number and host number parts can be chosen freely by
the local administrator; any bits in the local part can be used to form
the subnet accomplished. The division is done using a subnet mask
which is a 32 bit number. Zero bits in the subnet mask indicate bit positions
ascribed to the host number, and ones indicate bit positions ascribed to
the subnet number. The bit positions in the subnet mask belonging to the
network number are set to ones but are not used. Subnet masks are usually
written in dotted decimal form, like IP addresses.
The special treatment of ``all bits zero''
and ``all bits one'' applies to each of the three parts of a subnetted
IP address just as it does to both parts of an IP address which has not
been subnetted. See Special IP Addresses. For example, a subnetted Class
B network, which has a 16-bit local part, could use one of the following
schemes:
-
The first byte is the subnet number, the second
the host number. This gives us 254 (256 minus 2 with the values 0 and 255
being reserved) possible subnets, each having up to 254 hosts. The subnet
mask is 255.255.255.0.
-
The first 12 bits 15 are used for the subnet
number and the last four for the host number. This gives us 4094 possible
subnets (4096 minus 2) but only 14 hosts per subnet (16 minus 2). The subnet
mask is 255.255.255.240. There are many other possibilities.
While the administrator is completely
free to assign the subnet part of the local address in any legal fashion,
the objective is to assign a number of bits to the subnet number
and the remainder to the local address. Therefore, it is normal to use
a contiguous block of bits at the beginning of the local address part for
the subnet number because this makes the addresses more readable (this
is particularly true when the subnet occupies 8 or 16 bits). With this
approach, either of the subnet masks above are ``good'' masks, but masks
like 255.255.252.252 and 255.255.255.15 are not.
With the growth of the Internet, the name
space based on a 32-bit address is running out. Therefore, the IETF issued
an RFC for new generation of the IP protocol. The result is known as IP
new generation, IP version 6 or IPv6.
-
The IP Address Exhaustion Problem
The number of networks on the Internet
has been approximately doubling annually for a number of years. However,
the usage of the Class A, B and C networks differs greatly: nearly all
of the new networks assigned in the late 1980s were Class B, and in 1990
it became apparent that if this trend continued, the last Class B network
number would be assigned during 1994. On the other hand, Class C networks
were hardly being used.
The reason for this trend was that most
potential users found a Class B network to be large enough for their anticipated
needs, since it accommodates up to 65534 hosts, whereas a class C network,
with a maximum of 254 hosts, severely restricts the potential growth of
even a small initial network. Furthermore, most of the class B networks
being assigned were small ones. There are relatively few networks that
would need as many as 65,534 host addresses, but very few for which 254
hosts would be an adequate limit. In summary, although the Class A, Class
B and Class C divisions of the IP address are logical and easy to use (because
they occur on byte boundaries), with hindsight they are not the most practical
because Class C networks are too small to be useful for most organizations
while Class B networks are too large to be densely populated by any but
the largest organizations.
-
Private Internets
Another approach to conservation of the
IP address space is described in RFC 1597 - Address Allocation for Private
Internets. Briefly, it relaxes the rule that IP addresses are globally
unique by reserving part of the address space for networks which are used
exclusively within a single organization and which do not require IP connectivity
to the Internet. There are three ranges of addresses which have been reserved
by IANA for this purpose:
10 A single Class
A network
172.16 through
172.31 16 contiguous Class B networks
192.168.0 through
192.168.255 256 contiguous Class C networks
Any organization may use any addresses
in these ranges without reference to any other organization. However, because
these addresses are not globally unique, they cannot be referenced by hosts
in another organization and they are not defined to any external routers.
Routers in networks not using private addresses, particularly those operated
by Internet service providers, are expected to quietly discard all routing
information regarding these addresses. Routers in an organization using
private addresses are expected to limit all references to private addresses
to internal links; they should neither advertise routes to private addresses
to external routers nor forward IP datagrams containing private addresses
to via external routers. Hosts having only a private IP address do not
have IP-layer connectivity to the Internet. This may be desirable and may
even be a reason for using private addressing. All connectivity to external
Internet hosts must be provided with application gateways.
-
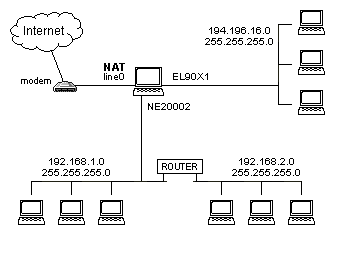
Network Address Translation
Network address translation (NAT) may be
used to achieve the following:
-
automatic local area network protection
-
a transparent connection of the network (or
its part) to the Internet using a single registered IP address
When NAT is employed, the local area
network does not use registered IP addresses. Because of this, the internal
structure of the network is hidden and not directly accessible from the
Internet. A mediator is needed to access the LAN from without. The NAT
module takes care of that. Since it remembers all communication initiated
from the protected network it only allows the packets which are an answer
to the initiated communication to enter the protected network. Other packets
are blocked.
The connection of an entire network using
a single registered IP address is made possible since the NAT module rewrites
the source address in the packets sent from computers in the local area
network with the address of the computer WinRoute is running on.
The connection to the Internet is transparent,
which means that the computers in the local network use WinRoute as their
gateway (router). From the point of view of the local computers it looks
as if they were connected to the Internet using registered addresses. Thus,
most applications work with the NAT without the need to setup anything
on the application's or server's side. This is the main feature which makes
NAT to differ significantly from various proxy servers and application-level
gateways that will in principle never be able to support some protocols.
-
How NAT Works
The NAT module maintains a table, which
records information about each connection. The main pieces of information
are: source IP address and port, target IP address and port, IP address
and port used to modify packets.
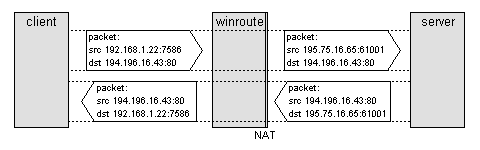
We may demonstrate the way NAT works using
the following example:
Let us consider a computer in a protected
network. The IP address of the computer is 192.168.1.22. The computer decides
to communicate from port 7658 with a WWW server in the Internet, the IP
address of which is 194.196.16.43 and its port number is 80. The communication
passes through WinRoute, which uses the address 195.75.16.75 on its outer
interface.
First, the computer 192.168.1.22 sends
a packet from port 7358 to computer 194.196.16.43, port 80. The packet
passes through WinRoute, which checks its table to see if it contains an
appropriate entry. If so, the existing entry is used, otherwise WinRoute
creates a new one. Then it modifies the packet so that it replaces the
source address to its own address. It also changes the source port. Thus
the source address will be 195.75.16.65, and the port number will for example
be 61001. After the changes the packet is sent on. When an answer arrives,
it contains 195.75.16.65 as the target address and 61001 as the target
port.
WinRoute searches its table by the port number 61001 and finds the entry
for the connection. According to the entry, it changes the target address
and port, back to 192.168.1.22 and 7658, respectively.
Please note:
Port numbers in the packets passing through
WinRoute must be modified, since if two or more stations in the protected
network start to communicate from the same port number, we need to identify
to which of the stations a packet belongs. The NAT module assigns port
numbers from the range of 61000 through 61600. A unique port is allocated
for each connection.
NAT Critical Points
Applications work with NAT without any problems
if the communication is initiated from the protected network. This is the
case with most applications. However, there are applications which are
not designed correctly and do not comply with the client-server model entirely.
Such applications may not work through NAT, or some of their functions
may be restricted. The reason is that these applications use more than
one connection and the additional connections are initiated by the server
(located somewhere in the Internet). Naturally enough, NAT blocks such
connections.
Security Policies, Firewalls and Packet
Filtering ...
-
IPv6
Addressing is only one of the modifications to the
IP protocol. Many other things have been changed. The address space not
only has been extended but the flexibility of addressing has been increased
by adding anycasting and scope to multicasting. There is also a capability
to add IPv6 addresses dynamically. A new field in the main header assigns
a particular packet to a flow, which may be a basis for allocating special
resources. The standard includes provisions for increased security through
a support for authentication and privacy. Instead of trailing options in
an IPv4 packet, IPv6 has a number of optional headers in addition to the
main header.
-
IPv6 Addressing
The new standard defines a new addressing space based
on a 128-bit address. The addressing schemes are more elaborated than in
IPv4 to accommodate increasingly sophisticated uses of the protocol.
It would be awkward to use the doted decimal notation
with 128-bit addresses. For example, imagine dealing with addresses like
the following:
105.220.136.100.255.255.255.255.0.0.18.128.140.10.255.255
Instead, the colon hexadecimal notation is used,
in which groups of 16 bits are put together as a hex number. The above
address looks simpler:
69DC:8864:FFFF:FFFF:0:1280:8C0A:FFFF
A sequence of zeros can be substituted by a double
colon, so:
FF0C:0:0:0:0:0:0:B1
becomes:
FF0C::B1
-
TCP
Although TCP is a connection-oriented protocol, it
is carried out transparently by a connection-less IP. IP packets are transmitted
unreliably; i.e., there is no guarantee that they will be delivered to
the destination. It is up to TCP to provide this kind of reliability. TCP
provides connection management, error recovery, multiplexing and flow control.
TCP communication is based on connections between
sockets. A socket is a number consisting of the IP address and a
16-bit port number (service access point). The IP address refers
to the host (node), while the port number indicates the application. It
is used for multiplexing, as a socket can accept multiple connections at
the same time. All ports with numbers below 1024 are reserved for standard
applications. These ports are called well-known ports. For example,
FTP uses port 21, Telnet 23, HTTP 80, SNMP 161, Mobile Agents 434.
To establish a connection, one of the parties, the
server, has to use the LISTEN primitive for anybody or for a specific source.
The other end, the client, has to invoke CONNECT to request establishing
of a connection. The parameters include the IP address, the port, maximum
size of transmitted segments (Maximum Transfer Unit, MTU)
and optional data like a password. If the listening process is willing
to satisfy the request for communication, then it uses the ACCEPT primitive
to send a positive acknowledgement to the client.
Any of the ends can use the SEND primitive to send
messages. If a segment is too long, then it is divided into smaller parts,
sent and then reassembled as the destination host. A sliding window
is used to ensure a proper flow of information; i.e., a timer is started
for each sent segment. If the segment is not acknowledged by the time the
timer expires, then the segment is resent. The maximum number of allowed
outstanding acknowledgements is determined by the size of the window. There
are number of algorithms that attempt to optimize this basic scheme.
A TCP connection is a byte stream. An application
sends messages by writing to the output stream associated with the connection
(similarly to writing to files). The size of the transmission segments
is determined by TCP. The PUSH flag in the header can be used to prevent
TCP from delaying transmission while waiting for more bytes to pack into
the current segment. The receiver obtains the data from connection by reading
from the input stream. The URGENT flag can be used to signal to the receiver
the reception of the message. In such case, the process would be interrupted
to give it an opportunity to read the urgent data.
-
UDP
UDP is a simple, connection-less transport protocol.
It is an unreliable protocol, because it does not guarantee delivery of
the messages. Any kind of reliability has top be implemented at the application
layer. It is targeted at applications that need to exchange small numbers
of messages without the overhead of establishing a connection.
For example, UDP is used by Simple Network Management
Protocol (SNMP), because in a failing network establishing a connection
might not be possible or not reliable.
-
DNS
Initially, it was relatively easy to manage a limited
number of IP addresses that a given host was to communicate with. A simple,
local text file was used to translate meaningful mnemonics to dotted decimal
notation. This solution is not a feasible solution for the communication
involving large numbers of nodes.
At the application layer of the communication protocol,
Domain
Name System (DNS) is used to provide mapping from text based
names that can be better understood by humans, to actual IP addresses that
can be used by the IP. A hierarchical, domain-based naming scheme
is fundamental for functioning of the network of DNS servers. DNS servers
are capable of resolving names sent to them via UDP by requesting applications.
The whole Internet is divided into domains,
which in turn are divided into subdomains, and so on. There are
plenty of generic and country top-level domains.
A single DNS server would not be practical for the
whole Internet, so usually one or two servers cover one of the non-overlapping
zones. If a DNS server is contacted with a request to resolve a name
in the same zone as the servers, then the name is in the servers registry,
and a corresponding address is returned. If the name is outside of the
zone, a request is sent to the DNS server for the top-level domain of the
name to resolve. This request can be forwarded to children zones in the
domain, until it reaches the server for the target zone. It is either resolved
there, and the address is returned, or the request fails. The returned
address can be kept for some time in the local cache.
Certain abbreviations are allowed, but they are not
handled by servers. A local name resolver can be programmed to try several
name
suffixes with the submitted name. For example, we do not need to use
a full name if the receiver of our email is in the same domain.
-
HTTP
Hypertext Transport Protocol has been designed to
transfer contents of a World Wide Web page from the server to the client
browser. Other protocols can also be used to transfer files, but they are
not suited to deal with file contents. The choice of the protocol is decided
by the client through specifying Universal Resource Locator (URL).
-
URL
URL specifies the location of the document that the
client is attempting to access and the protocol to use. For example:
http:/www.sce.carleton.ca/courses/
refers to the Web server running at www.sce.carleton.ca.
The HTTP protocol will be used to access the repository of courses. Servers
may listen on various ports for incoming requests, so there is a provision
for explicit port specification for non-standard ports. For example, the
following URL:
http://www.sce.carleton.ca:8080/dummy/
indicates that the request should be directed to
the port 8080 on to the Web server www.sce.carleton.ca. Only if the server
is listening on port 8080 will such a request reach it. By default, Web
servers listen on port 80.
Another example:
ftp:/ftp.sce.carleton.ca/paper.ps.gz
refers to the ftp server ftp.sce.carleton.ca. The
FTP protocol will be used to obtain a copy of the specified document.
Note that
http://www.sce.carleton.ca/paper.ps.gz
is also a valid URL. In this case, the HTTP protocol
is used. The advantage of this is that the presentation of the document
can be interpreted. For example, a program capable of handling compressed
files is invoked. Multipurpose Internet Mail Extensions (MIME)
has been invented by IETF to handle such translations.
-
MIME
MIME has been originally designed to allow sending
binary files as email messages. It has been adopted a standard way of sending
files over the Internet. In this scheme, the original file is encoded as
a text file and sent with an extra header that describes the type of the
file. The receiver needs a definition of handling for a specific type of
binaries. In our example, it might be:
MIME-Version: 1.0
Content-Type: application/x-gzipped
and have a decompressing application associated with
it (e.g., UNIX gzip or Windows WinZip).
-
HTTP
In spite of what the name may suggest, Hypertext
Transfer Protocol is used to transfer any type of information. It includes
plain text, Hypertext Markup Language (HTML) documents, video,
audio and other types that might be defined using MIME.
HTTP is a client/server transaction-oriented, stateless
protocol. The exchange of data occurs over a TCP connection. Each transaction
is carried out by an independent connection; i.e., the connection is dropped
after a single request has been satisfied. The client, a Web browser, sends
specially formatted request messages to the Web server. The server
responds with response messages that include a response line with
a response code.
The request line of a request message includes the
URL of the involved resource and the method; i.e., the command to
be performed by the Web server on the resource. They are called methods
rather than commands, to accommodate object-orientation in interactions
between the client and the server. Any name can be used for a method. If
the server implements the method, then it will be executed. Otherwise,
an error code will be sent back in the status line of the response message.
There are a number of standard methods specified in the HTTP RFC. They
must be implemented by every HTTP server.
The server may respond with a request for authentication,
if the access to the specified resource is limited. In that case, the client
is presented a challenge that indicates what authentication scheme
is used and what parameters are needed. Usually the client has to re-send
a request message with the authentication information that consists of
a user ID and a password. If the specified authentication information passes
the security checks, then the requested method is executed.
The request message may specify the date and time,
which is used to retrieve the specified document. The date and time describe
the age of the version of the resource that had been received in the past
and cached locally. If the resource on the server is newer than the cached
version, then it is sent by the server. Otherwise, the client will use
the version from the local cache.
Very often, there are intermediate nodes involved
in the HTTP communication. A proxy can be used on the client side of the
firewall to the external networks. In this case, the server must authenticate
itself to the firewall before a connection between the proxy and the server
is allowed. All requests from the client are handled by the proxy, which
acts as an intermediary. The content carried over the connection might
be controlled and statistics can be collected. A similar security proxy
can be installed on the server side of the firewall.
Another intermediary can be a gateway, which can
provide transparent services by other servers such as FTP or Gopher. If
a request is directed (for example) to FTP (as specified in the URL), then
the gateway will contact the FTP server. The retrieved documents are converted
to the format acceptable to the HTTP protocol.
The RFCs for HTTP use the term Universal Resource
Identifier (URI), but at this moment, URL is used for practical
purposes. URI is a generalization of a WWW identifier. URI specifies the
resource without the location or the protocol to obtain it. Generally,
the resource is of interest, and not how and from it is retrieved. URL
is a type of URI with a specific access protocol and an Internet address
of the host.
-
HTML
HTML is a formatting language. Formatting languages
like HTML, SGML, TeX, etc. are used to format complex, multimedia documents
by embedding the content into formatting phrases. Each phrase is surrounded
by formatting tags that define its beginning and the end. HTML tags are
enclosed by < and >. Each phrase starts with a starting
tag that specifies the operation on the content. A phrase ends with an
ending tag, which is the same as the starting tag, but is preceded by /.
For
example, HTML uses <P> and </P> to embed a text that
should constitute a paragraph of a document. Certain phrases can be embedded
into others. The starting tag can be followed by parameters that provide
details of the operation. Certain tags do not require ending tags; e.g.,
<FRAME>. The HTML is a unique formatting language because of its built-in
support for online resources (e.g., hyperlinks, applets, forms, frames,
maps, etc.).
The general structure of an HTML document is as follows:
<HTML>
<HEAD>
<TITLE>
text of the title
</TITLE>
</HEAD>
<BODY>
body of the document
</BODY>
</HTML>
The following table describes some of the HTML tags:
| <B
></B>
<I
></I>
<U
></U>
<SUP
></SUP>
<SUB
></SUB>
<FONT
> |
Some of the character
formatting tags for bold, italic, underlined, superscript, subscript, font
definition. |
| <BR
> |
New line. |
| <HR
> |
Separator line. |
| <P
>
</P> |
Paragraph formatter. |
| <Hn></Hn>
n = 1..6 |
Headers levels 1 to 6. |
| <PRE
>
</PRE> |
Preformatted text. The
content of this phrase appears exactly as in the original document. No
formatting is performed. |
| <OL
>
<LI
>
</LI>
</OL> |
Ordered (numbered) list
formatting with embedded list items.
<UL> refers to unordered (bulleted) list. |
| <DL
>
<DT
>
</DT>
<DD
>
</DD>
</DL> |
Definition list with embedded
items consisting of a definition term followed by a definition description. |
| <TABLE
>
<TR>
<TD>
</TD>
</TR>
</TABLE> |
Table consisting of table
rows that include a number of table cells. |
| <A HREF="..."
>
</A> |
A hyperlink. HREF parameter
takes a URL with a possible named target as a hash preceded suffix (see
the next row). |
| <A NAME="..."
>
</A> |
Definition of a named
target in the document. |
| <IMG SRC="..."
> |
Embedded image. |
<IMG
SRC="..."
ISMAP
USEMAP="..."
>
<MAP NAME="...">
<AREA
COORDS="..."
SHAPE=rect|circle|polygon
HREF="..."
>
</MAP> |
Using an image as a click
sensitive map. The name of the map is used in the image tag, which has
to be tagged as a map. Clicking in the defined area surrounding the specified
coordinates activates the associated hyperlink. |
<APPLET
CODE="..."
CODEBASE="
"
WIDTH="..."
HEIGHT="..."
>
<PARAM
>
</APPLET> |
Embedded Java applet.
CODE specifies the main Java class. Codebase specifies the reference root
location of all of the involved classes, unless a full URL is specified.
PARAM is used to pass parameters to the applet. |
| <FRAMESET
>
<FRAME SRC="..."
>
<NOFRAMES
>
</ NOFRAMES >
</FRAMESET> |
Creating frames within
a Web page. There might several frames within one set. The NOFRAMES tag
refers to the area that is processed only if there is no support for frames. |
| <FORM ACTION="..."
>
<INPUT
>
<SELECT NAME="...">
<OPTION
>
</OPTION
</SELECT>
<TEXTAREA NAME="..."
>
</TEXTAREA>
</FORM> |
Using forms to acquire
input from the user. The ACTION parameter determines the CGI-BIN script
to invoke to handle the input.
INPUT defines a single entry field.
SELECT NAME defines a menu of choices specified by
a number of options.
The TEXTAREA tag can be used to obtain multi-line
input. |
Note: Most people use "Composers"
to write HTML
There are important limitations of HTML in that
it is not extensible, does not allow for creating structured documents
(e.g., object-oriented hierarchies) and does not provide mechanisms for
validation of documents. All of such features are needed to create complex
database repositories of Web documents. SGML, on which HTML was based,
is far richer, but includes many features, that are not needed in the Web
context. A subset of SGML has been defined that provides the missing capabilities.
It is called Extensible Markup Language (XML).
Background: HTML and SGML
Most documents on the Web are stored and transmitted
in HTML. HTML is a simple language well suited for hypertext, multimedia,
and the display of small and reasonably simple documents. HTML is based
on SGML (Standard Generalized Markup Language, ISO 8879), a standard system
for defining and using document formats.
SGML allows documents to describe their
own grammar -- that is, to specify the tag set used in the document and
the structural relationships that those tags represent. HTML applications
are applications that hardwire a small set of tags in conformance with
a single SGML specification. Freezing a small set of tags allows users
to leave the language specification out of the document and makes it much
easier to build applications, but this ease comes at the cost of severely
limiting HTML in several important respects, chief among which are extensibility,
structure, and validation.
-
Extensibility. HTML does not allow
users to specify their own tags or attributes in order to parameterize
or otherwise semantically qualify their data.
-
Structure. HTML does not support the
specification of deep structures needed to represent database schemas or
object-oriented hierarchies.
-
Validation. HTML does not support the
kind of language specification that allows consuming applications to check
data for structural validity on importation.
In contrast to HTML stands generic
SGML. A generic SGML application is one that supports SGML language specifications
of arbitrary complexity and makes possible the qualities of extensibility,
structure, and validation missing from HTML. SGML makes it possible to
define your own formats for your own documents, to handle large and complex
documents, and to manage large information repositories. However, full
SGML contains many optional features that are not needed for Web applications
and has proven to have a cost/benefit ratio unattractive to current vendors
of Web browsers.
The XML effort
The World Wide Web Consortium (W3C) has created
an SGML Working Group to build a set of specifications to make it easy
and straightforward to use the beneficial features of SGML on the Web.
See the W3C SGML
Activity page for the current status of this effort. The goal
of the W3C SGML activity is to enable the delivery of self-describing data
structures of arbitrary depth and complexity to applications that require
such structures.
The first phase of this effort is the specification
of a simplified subset of SGML specially designed for Web applications.
This subset, called XML (Extensible Markup Language), retains the key SGML
advantages of extensibility, structure, and validation in a language that
is designed to be vastly easier to learn, use, and implement than full
SGML.
XML differs from HTML in three major respects:
-
Information providers can define new tag and
attribute names at will.
-
Document structures can be nested to any level
of complexity.
-
Any XML document can contain an optional description
of its grammar for use by applications that need to perform structural
validation.
XML has been designed for maximum expressive
power, maximum teachability, and maximum ease of implementation. The language
is not backward-compatible with existing HTML documents, but documents
conforming to the W3C HTML 3.2 specification can easily be converted to
XML, as can generic SGML documents and documents generated from databases.
An initial
working draft for XML 1.0 has been released for public discussion.
A complete specification that includes methods for associating hypertext
linking and stylesheet mechanisms with XML documents is scheduled for release
at the Sixth World Wide Web Conference in April, 1997.
Web applications of XML
The applications that will drive the acceptance
of XML are those that cannot be accomplished within the limitations of
HTML. These applications can be divided into four broad categories:
-
Applications that require the Web client to
mediate between two or more heterogeneous databases.
-
Applications that attempt to distribute a
significant proportion of the processing load from the Web server to the
Web client.
-
Applications that require the Web client to
present different views of the same data to different users.
-
Applications in which intelligent Web agents
attempt to tailor information discovery to the needs of individual users.
The alternative to XML for these applications
is proprietary code embedded as "script elements" in HTML documents and
delivered in conjunction with proprietary browser plug-ins or Java applets.
XML derives from a philosophy that data belongs to its creators and that
content providers are best served by a data format that does not bind them
to particular script languages, authoring tools, and delivery engines but
provides a standardized, vendor-independent, level playing field upon which
different authoring and delivery tools may freely compete.
http://www.xml.com/xml/pub/98/10/guide1.html
Dynamic HTML and Cascading Style Sheets (CSS)
A powerful partnership: DHTML and CSS
CSS brings powerful layout and designcapabilities
to DHTML. With CSS, you can specify font sizes and faces, margin heights
and widths, borders and padding, even text decoration. In addition, using
CSS you can create absolutely positioned content. No longer do you have
to toil with complex and limited tables; now content can be contained within
movable, malleable blocks. This visual control and accuracy, when combined
with scripting languages and powerful object models, gives web authors
the power to make any document more engaging.
Introducing CSS
CSS is a language in itself, one of the many languages
that you'll need to know to master DHTML. The purpose of CSS is to define
styles for a document's content. A style can instruct a word to be blue
or specify that the text on the first line of a paragraph be capitalized.
CSS allows its styles to be grouped, associated, and applied to specific
elements.
Understanding styles
A style is a grouping of properties that define how
an HTML element will appear in a document. For example, a CSS style could
say, "make this text green, 24 points, and give it a left margin of 5 pixels."
<DIV STYLE = "color:
green; font-size: 24pt; margin-left: 5px"> Green Giant </DIV>
Notice that the text is surrounded by a DIV tag.
For a style to be applied to an HTML element, that element must be contained
by a tag (such as DIV, A, SPAN or even P). Inside the tag, there's a special
attribute, STYLE, in which the CSS style for the element is defined.
The CSS syntax is very different from that of HTML.
First, each property (for example, color and font-size) is separated from
its value by a colon [:]. Property-value combinations are separated by
semi-colons [;]. If you take a close look at these style properties, you'll
see that they do what they say. The color property defines the text's color,
the font-size property defines the text's point size, and so on.
There are many style properties in the CSS specification.
To learn more about them, visit the World
Wide Web Consortium's CSS reference page.
Grouping styles: classes and style sheets
The previous example shows a single style being applied
to a single element. This is called an inline style. When you group multiple
style properties together between STYLE tags, you create a style
sheet.
<STYLE>
.greengiant { color: green;
font-size: 24pt;
margin-left: 5px;
}
.littlered
{ color: red;
font-size: 12pt;
}
</STYLE>
This style sheet contains two unique groupings of CSS
style properties, named
greengiant and
littlered. The
names of these groupings are referred to as classes. Class names are preceded
by a period [.], and the style properties that comprise the classes (for
example, font-size) are placed between opening and closing curly braces.
This is the syntax for creating classes of styles within a style sheet.
Once a class had been defined in the style sheet,
it can be applied to any HTML elements on the page. To apply a class from
a style sheet to an element on the page, surround the target element with
a tag and add the CLASS attribute with the name of the class (leave off
the preceeding period).
<DIV
CLASS = "littlered">
Riding Hood
</DIV>
This example applies the style attached to the littlered
class to the text enclosed in the DIV tags. Based on the style properties
defined for the littlered class, the text would appear in a red,
12 point font.
Applying styles to existing tags
In addition to applying CLASS styles to tags, you
can also apply styles directly to the tags themselves. For example, all
of the links on a page could be made to have no underlining, or all P tags
could indent the first line by 5 pixels.
<STYLE>
A { color: green;
font-size: 24pt;
text-decoration: none;
}
</STYLE>
In this example, all of the links in the document will
appear in a 24 point green font with no underline. The syntax is almost
the same as with classes, except that the grouping of styles is given the
name of the target tag (in this case A) instead a unique class name preceeded
by a period.
Absolute positioning
CSS has properties that enable absolute positioning
of HTML elements, allowing content to be placed at exact x, y, and z coordinates.
This gives you more control over the layout of a page, and when combined
with DHTML, allows you to animate absolutely positioned content.
To create absolutely positioned elements with CSS,
first create classes for the elements that need to be absolutely positioned
(or use inline styles), then apply those classes to the elements on the
page. The following code creates an absolutely positioned piece of text:
<HEAD>
<STYLE>
.hilda { position: absolute;
top: 100px;
left: 50px;
visibility:
visible;
z-index: 1;
color:
#008000;
font-family: times;
font-size:
72px;
}
</STYLE>
</HEAD>
<BODY>
<DIV
CLASS = "hilda">Hello
Hilda</DIV>
</BODY>
The style sheet class in this example, hilda,
is initially defined as an absolutely positioned class--its position property
is set to absolute rather than relative.
The left and top properties define the x and y coordinates.
The left property determines the location of an element's left side relative
to the left side of the document, and the top property determines the location
of an element's top side relative to the top of the document. In this example,
the text that this class is applied to is positioned 100 pixels from the
top of the page (top: 100px) and 50 pixels from the left of the page (left:
50px).
The visibility and z-index properties are also important.
The visibility property specifies whether an element is hidden or visible.
The z-index property controls the layering of an element. If two elements
overlap, the element with the higher z-index will appear on top.
Controlling CSS through DHTML
In theory, scripting languages like JavaScript and
VBScript have access to every property of a CSS style through the document
object model. This means that a style applied to a link could change when
the mouse is moved over it, the text of an article could expand in size
when the reader selects it, or an absolutely positioned element could move
across the page when clicked. In practice, only IE 4 has access to all
the CSS style properties. Navigator 4's script access is limited to the
absolute positioning properties (left, top, z-index, and visibility).
IE 4and Navigator 4 also have different ways of referring
to elements in a document. The following example illustrates these differences
and how to access the style properties of HTML elements through the document
object model.
<DIV ID = "hildaElement"
CLASS = "hilda">Hello Hilda</DIV>
Notice that the new attribute ID has been added to
the DIV tag. (The ID attribute and the NAME attribute are identical
in terms of the document object model: either one can define an HTML element's
unique name.) To access
hildaElement's style properties in Navigator,
the JavaScript syntax is:
document.hildaElement.styleProperty;
In this example, document is the object
that represents the document, hildaElement is the HTML element
with the ID
hildaElement, and styleProperty is a given
style property of that element, such as z-index.
To access this same element and its style properties
in IE, the JavaScript (actually JScript, Microsoft's JavaScript-like language)
syntax is:
document.all.hildaElement.style.styleProperty;
Notice that there are two additional objects in this
example: the
all object after document, and the
style
object between hildaElement and its style property.
Because the IE document object model is currently
more expansive that the Navigator object model, the remaining code examples
will refer to IE's syntax and capabilities. See "Handling
CSS compatibility issues" later in this document for more information.
Dynamic styles
Based on the explanations in the previous section,
understanding how to access and control the style properties of HTML elements
is relatively simple. In this example, a selection of text is surrounded
by a DIV tag which has a CLASS attribute that points to a style
sheet class named
smallgreen:
<DIV CLASS =
"smallgreen" ID = "smallbig">
Small is
Big
</DIV>
Once the HTML element is given a unique name with the
ID attribute, a script can control the style properties of the element.
For example, to change the font-size property of
smallbig, access
the element's style property and from there its fontSize property.
(fontSize is the same property that CSS uses to control font-size,
but because of naming limitations in scripting languages, the hyphen is
replaced with an intercap.)
document.all.smallbig.style.fontSize
= 24;
To change smallbig's color to blue, simply
repeat the above process, substituting color for
fontSize.
document.all.smallbig.style.color
= "blue";
Dynamic positioning
Controlling the absolute positioning of HTML elements
is similar to controlling an element's style properties. However, you can
use special techniques with absolute positioning to achieve such effects
as animation and gradual movement.
For example, to move an HTML element from one part
of the page to the other, you could simply change the left or top properties
of the element like this:
document.all.someElement.style.left
= 100;
To achieve more control you can use functions to
incrementally move the element. This JavaScript function, for example,
slides the element from the top of the page to the bottom:
function slideElement(theElement, from, to) {
if (from
< to) {
theElement.style.top = (from += 10);
setTimeout('slideElement(' + theElement + ',' + from + ',' + to + ')',
50);
}
}
To use this function, pass it the target element, the
initial top coordinate, and the final top coordinate:
slideElement(document.all.someElement,
0, 30 0);
When the function is run, it moves the element down
the page 10 pixels at a time until it's 300 pixels from the top.
It works like this: the function is initially passed
values of 0 and 300 as parameters from and to. It's also
passed the element that will be moved, document.all.someElement.
If
from is less than to, the function increases the value
of from by 10 and gives that number to the HTML element's top
property, thereby moving the object down the page 10 pixels at a time.
The setTimeout() method repeats the function every 50 milliseconds, continuing
the process until the HTML element is 300 pixels from the top of the page.
Another simple effect is hiding and showing HTML
elements using the onMouseOver and
onMouseOut event handlers.
You only need two small functions for this:
function showElement(theElement) {
element.style.visibility = 'visible';
}
function hideElement(theElement)
{
theElement.style.visibility = 'hidden';
}
Pass each of these functions the name of the element
to be hidden or shown. For example, when the mouse is moved over the link
below, an element called
desc is made visible:
<A HREF
= "home.html"
onMouseOver = "showObject(document.all.desc)"
onMouseOut
= "hideObject(document.all.desc)">Home</A>
Handling CSS compatibility
issues
You can easily resolve the CSS compatibility issue
by adding some additional JavaScript code to your document. This code begins
by determining which browser is being used:
var isNS =
(navigator.appName == 'Netscape' &&
parseInt(navigator.appVersion) >= 4);
Here a variable,
isNS, tells you if the browser
is Navigator 4 or not. After determining the browser, use a conditional
to assign the HTML elements on the page to shortcut variables which will
be accessible to both browsers. This example creates a variable called
hildaRef that will be used to reference hildaElement's
style properties.
var hildaRef = (isNS) ?
document.hildaElement : document.all.hildaElement.style;
The variable
hildaRef is set equal to document.hildaElement
if the browser in use is Navigator 4, and document.all.hildaElement.style
if it's not Navigator 4. The assumption is that if the browser isn't Navigator
4, it's IE 4 (a rather dangerous assumption; you'll probably want to do
additional checks before this to weed out non-DHTML browsers). To use this
code, put the actual HTML element in place of theElement.
After giving the HTML element to a shortcut variable,
it can be controlled through the shortcut variable in both Navigator and
IE. For example, the syntax to change the left property of hildaElement
is:
hildaRef.left = 100;
http://www.dhtmlzone.com/articles/
Mobile IP
A typical user might usually connect to the network
at their desk but occasionally will take their computer to a conference
room in another part of the building, or even at another site. However,
today's networking protocols, including the TCP/IP and the OSI protocol
suites, have been designed under the tacit assumption that computers are
always attached to the network at a single physical location. Today, host
migration is assumed to occur so rarely that it can be handled manually.
For example, consider the process of host migration in the above scenario
using the IP protocol. If the user's desk and the conference room have
direct access to the same IP subnet then the migration process is trivial.
Otherwise, the user must acquire a new IP address. After acquiring a new
address from the appropriate local authority, which may not be an easy
task, numerous con�guration �les on the migrating machine, on various name
servers and on other machines (that use the original IP address to identify
the migrating machine) need to be modied. This migration process does achieve
host migration but only after a slow, error prone configuration procedure
that a typical user does not have the skills or desire to carry out. In
addition, the computer then has a completely different identity and so
all existing network applications must be restarted. Clearly, new protocols
are needed to ensure that host migration can be achieved transparently
to the user. Ease of migration will become even more important as wireless
network interfaces become widely available. Once the user is unconstrained
by cable it is likely that frequent network migration will become common.
Host migration may not even be under the user's control. For example, if
a mobile host operates in overlapping wireless cells it may migrate from
cell to cell based on dynamic factors such as load and noise. The new protocols
will not only have to be transparent but also efficient so that they can
handle rapid network migration. Increasingly, computer networks are being
interconnected into a single global network. The Internet is a good example
of a growing global network. Users already have access to network facilities
anywhere in the world, and not just in the local area. The new protocols
should therefore be designed to operate both locally and in the wide area.
Put simply, under the current Internet Protocol, if the mobile host moves
without changing its address, it will lose routing; but if it does change
its address, it will lose connections.
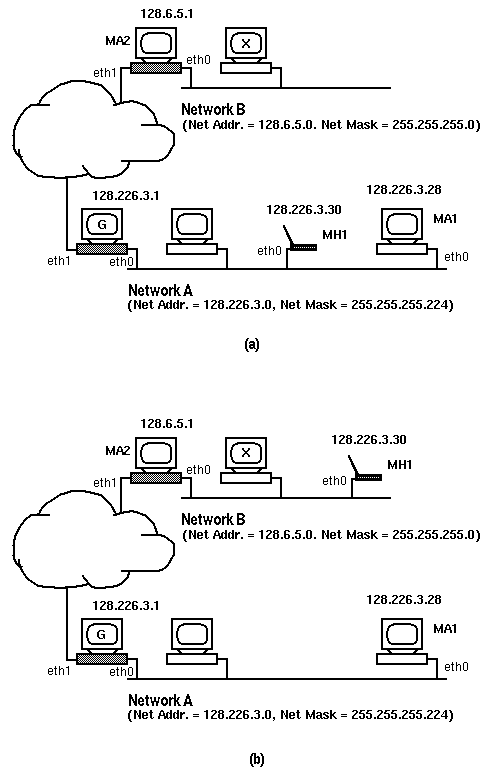
Figure 1: A wired internetwork with mobility support.
In (a), the mobile host MH1 is home. In (b), MH1 is visiting
Network B.
Mobile-IP is an enhancement to IP which allows a
computer to roam freely on the Internet while still maintaining the same
IP address. The Internet Engineering Task Force (IETF) is currently developing
a Mobile-IP standard which. The Mobile-IP architecture, as proposed by
the IETF, defines special entities called the Home Agent (HA) and Foreign
Agent (FA) which cooperate to allow a Mobile Host (MH) to move without
changing its IP address. The term mobility agent is used to refer to a
computer acting as either a Home Agent, Foreign Agent, or both. A network
is described as having mobility support if it is equipped with a mobility
agent.
Each Mobile Host is associated with a unique home
network as indicated by its permanent IP address. Normal IP routing always
delivers packets meant for the MH to this network. When a MH is away, a
specially designated computer on this network, its Home Agent, is responsible
for intercepting and forwarding its packets. The MH uses a special registration
protocol to keep its HA informed about its current location. Whenever a
MH moves from its home network to a foreign network, or from one foreign
network to another, it chooses a Foreign Agent on the new network and uses
it to forward a registration message to its HA.
After a successful registration, packets arriving
for the MH on its home network are encapsulated by its HA and sent to its
FA. Encapsulation refers to the process of enclosing the original datagram
as data inside another datagram with a new IP header. This is similar to
the post office affixing a new address label over an older label when forwarding
mail for a recipient who has moved. The source and destination address
fields in the outer header correspond to the HA and FA, respectively. This
mechanism is also called tunneling since intermediate routers remain oblivious
of the original inner IP header. In the absence of this encapsulation,
intermediate routers will simply return packets back to the home network.
On receiving the encapsulated datagram, the FA strips off the outer header
and delivers the newly exposed datagram to the appropriate visiting MH
on its local network.
Host movements typically cause some datagrams to
be lost while routing tables at the HA and FA re-adjust to reflect the
move. However, by using retransmissions and acknowledgments, connections
maintained by the transport layer protocol are able to survive these losses
in the same way they survive losses due to congestion. Note that even when
the MH is away, datagrams meant for it are always first sent to its home
network, in many cases resulting in a non-optimal route.
Figures 1(a) and 1(b) show a mobility-supporting
internetwork which serves as an illustrative example. It shows two mobility
supporting networks, Network A and Network B, which are equipped with mobility
agents MA1 and MA2, respectively. A mobile host, MH1, is also shown, whose
home network is Network A. Whenever MH1 is away, MA1 acts as its home agent.
When MH1 visits Network B, MA2 acts as its foreign agent. It is worth
pointing out that changes introduced by Mobile-IP are independent of the
communication medium in use. Even though this figure shows mobility support
in a wired internetwork, the Mobile-IP works just as effectively in a wireless
environment.
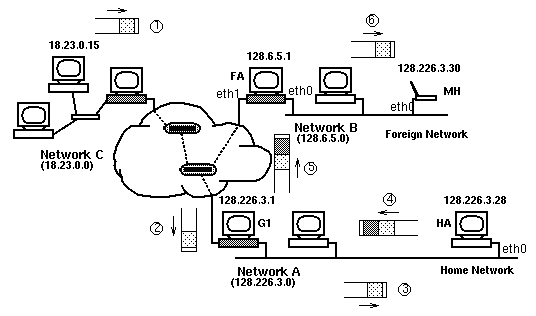
Figure 2: IP datagram flow to a mobile host that
is away from its home network.
Figure 2 further illustrates the main idea behind
Mobile-IP. It shows an IP datagrm as it flows from computer A (IP address
18.23.0.15) to the mobile host (IP address 128.226.3.30). In this figure,
the mobile host is shown to be away from its home network. Hosts MA1 (IP
address 128.226.3.28) and MA2 (IP address 128.6.5.1) are acting as its
home agent and foreign agent, respectively.
The IP header in the datagram as it leaves A indicates
128.226.3.30 as the destination. In Figure 2, this header is shown as the
dotted portion of the datagram. Therefore, this datagram is routed to Network
A (steps 1 and 2). Here, the home agent picks up the datagram and inserts
an additional IP header before re-injecting it into the network (steps
3 and 4). The new IP header carries 128.6.5.1 as its destination address.
This header is shown in grey in Figure 2. As this is the header seen by
intermediate routers like R1, the datagram is correctly routed to the foreign
agent (step 5). By this time, the registration process has already informed
the foreign agent of the mobile host's presence on the local net. When
the encapsulated datagram arrives at MA2, the outer header is stripped.
The newly exposed header reveals the MH as the destination and the datagram
is forwarded appropriately (step 6).
The IETF Mobile-IP draft also allows a Mobile Host
to do its own decapsulation. In this case, the MH must aquire a temporary
IP address on the foreign network (e.g. using DHCP) to be used for forwarding.
This allows a mobile host to receive datagrams away from its home network
even in the absence of a Foreign Agent. The downside of this approach is
that the kernel on the MH must now be modified to handle encapsulated datagrams.
Overview of Mobility Support in IPv6
From the model of operation enabling mobile networking
for IPv4, the authors of the Mobile borrow the concepts of home network,
home address, home agent, care-of address, and binding. Mobile computers
are assigned (at least) two IPv6 addresses whenever they are roaming away
from their home network. One (the home address) is permanent; the other
(the IPv6 link-local address) is used temporarily. In addition, the mobile
node will typically autoconfigure figure a globally-routable address at
each new point of attachment. Every IPv6 router supports encapsulation,
so every router is capable of serving as a home agent on the network(s)
to which it is attached.
Using IPv4 terminology, the basic model of operation
in IPv6 assumes that mobile node can always be reached by sending packets
to its home (permanent) address. Whenever the mobile node is not present
on its home network, packets arriving for it there will be intercepted
by the home agent, and tunneled to a care-of address.
Care-of addresses can be constructed by the mobile
node using the methods of automatic address configuration. If the mobile
node receives router advertisements, it must use automatic address configuration
to construct a globally unique, routable address. This routable address
can be used by the mobile node as its care-of address.
After determining its care-of address, a mobile node
must send a binding update containing that care-of address to the home
agent (and any other correspondent nodes that may have out-of-date bindings
in their binding cache). By default, correspondent nodes send packets to
mobile nodes by using routing headers instead of encapsulation. As detailed
in the next section, correspondent nodes are usually expected to deliver
packets directly to the mobile node's care-of address, so that the home
agent is rarely involved with packet transmission to the mobile node.
It is essential for scalability and minimizing network
load that correspondent and to be able to cache this information for use
in sending future packets to the mobile node's care-of address. By caching
the care-of address of a mobile node, optimal routing of packets can be
achieved between the correspondent node and the mobile node. Routing packets
directly to the mobile node's care-of address also eliminates congestion
at the home agent and thus contributes significantly to the overall health
of the Internet.
Moreover, many communication events between mobile
nodes and correspondent nodes can be carried out with no assistance from
the home agent. Thus, the impact of failure at the home agent can be drastically
reduced; this is important because many administrative domains will have
a single home agent to serve a particular home network, and thus a single
point of failure for communications to nodes using that home agent.
Communications between the home agent and a mobile
node may depend on a number of intervening networks. Thus, there are many
more ways that packets can fail to reach a mobile node when the home agent
is required as an intermediate node. This would be particularly relevant
on, say, trans-oceanic links between home agent and mobile enables communication
with the mobile nodes even if the home agent fails or is difficult to contact
over the Internet.
In the typical case, when a mobile node has configured
its care-of address at one of its own interfaces, transferring data to
the mobile attachment, than transferring data to any other node on that
link. This improves performance further.
More Information at:
www.rs6000.ibm.com/resource/aix_resource/Pubs/redbooks/htmlbooks/gg243376.04/3376fm.html
Note: Some of the information is dated!